Program: High Performance Knowledge Bases, DARPA Sponsoring Agency: AFOSR Principle Investigator: Gheorghe Tecuci
Phone: (703) 993-1722, E-mail: tecuci@gmu.edu
Learning Agents Laboratory
Computer Science Department
George Mason University, Fairfax, VA 22030
Abstract
We propose to develop advanced knowledge acquisition technology based on apprenticeship multistrategy learning and agent-assisted collaboration. This technology will allow collaborating teams of domain experts, with little or no knowledge base or computer experience, to easily build large, comprehensive knowledge bases (KB) by extending existing foundation theories, defining additional domain theories and problem solving strategies, and acquiring domain facts. Moreover, this technology will produce validated knowledge bases and will allow easy modification of the KB in response to changes in the environment or in the requirements of the application.
This technology will be implemented into a Collaborative Knowledge Acquisition Toolkit (KA Toolkit) that consists of a collection of integrated tools for KB translation, browsing and editing, rule learning, KB refinement, exception handling, and collaboration management. The KA Toolkit will be used by software/knowledge engineers to rapidly (within weeks) develop customized Knowledge Acquisition Agents (KA Agents). The KA Agents will allow a collaborating team of domain experts to rapidly (within months) build a large KB. Each expert will interact with a personal KA Agent to build a portion of the KB, to integrate it within the KB, and to communicate with the other experts.
The main feature of this approach is that the experts communicate their expertise to the KA Agents in a very natural way, as they would communicate it to human apprentices. For instance, an expert may teach his/her KA Agent how to solve a certain type of problem by providing a concrete example, helping the agent to understand the solution, supervising the agent as it attempts to solve analogous problems, and correcting its mistakes. Through only a few such natural interactions, the agent will be guided into learning complex problem solving rules, and in extending and correcting the KB. This KA process is based on a cooperation between the KA Agent and the human expert in which the agent helps the expert to express his/her knowledge using the agent's representation language, and the expert guides the learning actions of the agent. The central idea is the use of synergism at several levels. One is the synergism between teaching (of the agent by the expert) and learning (from the expert by the agent). For instance, the expert may select representative examples to teach the agent, may provide explanations, and may answer agent's questions. The agent, on the other hand, will learn general rules that are difficult to be defined by the expert, and will consistently integrate them into the KB. Another is the synergism between different learning methods employed by the KA Agent. By integrating complementary learning methods (such as inductive learning from examples, explanation-based learning, learning by analogy, learning by experimentation) in a dynamic, task-dependent way, the agent is able to learn from the human expert in situations in which no single strategy learning method would be sufficient. Besides acquiring knowledge from the domain experts, the KA Agents will also act as communication, partitioning and integration agents, helping the experts to collaborate.
We plan to coordinate the development of the KA Toolkit with the development of the other tools supported by the HPKB program, in order to facilitate their integration into a Knowledge Base Development Environment.
The basis for the proposed KA Toolkit is the Disciple Toolkit that we have built with partial support from the DARPA CAETI Program. Without being a collaborative toolkit, the Disciple Toolkit already contains initial versions of some of the tools that we propose to develop, and therefore illustrates some of the features of the KA Toolkit.
Technical Rationale
Developing principles, methods and systems for building knowledge bases has long been a goal of two areas of Artificial Intelligence: Knowledge Acquisition and Machine Learning. The focus of Knowledge Acquisition has been to improve and partially automate the acquisition of knowledge from an expert by a knowledge engineer (Buchanan and Wilkins, 1993). Knowledge Acquisition has had limited success, mostly because of the communication problems between the expert and the knowledge engineer, which require many iterations before converging to an acceptable knowledge base. In contrast, Machine Learning has focused on autonomous algorithms for acquiring and improving the organization of knowledge (Shavlik and Dietterich, 1990; Michalski and Tecuci, 1994; Mitchell, 1997). However, because of the complexity of this problem, the application of Machine Learning tends to be limited to simple domains. While Knowledge Acquisition research has generally avoided using machine learning techniques, relying on the knowledge engineer, Machine Learning research has generally avoided involving a human expert in the learning loop. We assert that neither approach is sufficient, and that the process of building knowledge bases should be based on a direct interaction between a human expert and a learning system (Tecuci, 1992a,b). Indeed, a human expert and a learning system have complementary strengths. Problems that are extremely difficult for one may be easy for the other. For instance, automated learning systems have traditionally had difficulty assigning credit or blame to individual decisions that lead to overall results, but this process is generally easy for a human expert. Also, the "new terms" problem in the field of Machine Learning (i.e. extending the representation language with new terms when these terms cannot represent the concept to be learned), is very difficult for an autonomous learner, but could be quite easy for a human expert (Tecuci and Hieb, 1994). On the other hand, there are many problems that are much more difficult for a human expert than for a learning system as, for instance, the generation of general concepts or rules that account for specific examples, and the updating of the KB to consistently integrate new knowledge.
Technical Approach
Based on these observations we propose an integrated machine learning and knowledge acquisition approach to the problem of building knowledge bases (Tecuci and Kodratoff, 1995; Tecuci, 1995). The basic scenario for this approach involves a Knowledge Acquisition Agent (KA Agent) that acts as an apprentice to a human expert and learns from the expert. The KA Agent has advanced communication, knowledge elicitation, and multistrategy learning capabilities that allows it to interact with the expert in a manner that is natural for the expert. This allows the expert to teach the agent in much the same way the expert would teach a human apprentice. For instance, the expert may teach the agent how to solve a certain type of problem (such as placing the platoons of a company to defend its area of responsibility against an enemy attack) by providing an example of how to solve this problem, by helping the agent understand why this is a correct solution, and by supervising the agent as it solves similar problems and, if necessary, correcting its solution and helping it to understand its mistakes. The advanced communication techniques employed by the agent will help the expert in expressing his/her knowledge using agent's representation language. They will also allow the expert to guide the learning actions of the agent. The advanced knowledge elicitation techniques employed by the agent will direct the expert in providing missing information. The various learning strategies employed by the agent will allow it to learn from a variety of information, to extend, refine, and update the knowledge base.
Using such an approach we propose to develop advanced knowledge acquisition technology that will allow groups of domain experts with little or no knowledge base or computer experience, to easily build large, comprehensive knowledge bases by extending existing foundation theories, defining additional domain theories and problem solving strategies, and acquiring domain facts. Moreover, this technology will produce validated knowledge bases and will allow easy modification of the KB in response to changes in the environment or in the requirements of the application.
Constructive Plan to Accomplish Technical Goals
This technology will be implemented into a Collaborative Knowledge Acquisition Toolkit (KA Toolkit) to be rapidly (within weeks) customized by software/knowledge engineers into KA Agents for specific application domains.
The overall architecture of the KA Toolkit is presented in Figure 1. The KA Toolkit will be built using the Disciple Toolkit as a basis. Therefore some of its browsing, editing, rule learning and KB refinement tools are improved versions of the corresponding Disciple tools.
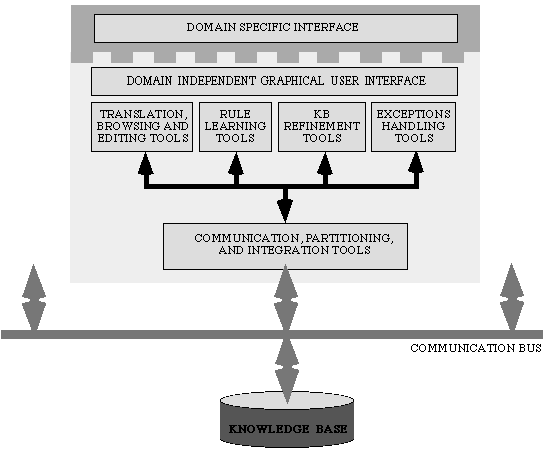
Figure 1: Overall Architecture of the Knowledge Acquisition Toolkit.
To customize the KA Toolkit into a set of KA Agents for a specific application domain the software/knowledge engineer has only to develop a domain specific interface on top of the domain independent graphical user interface of the KA Toolkit. This domain specific interface will allow the domain experts to express their knowledge in an as natural way as possible. The knowledge elicitation and learning tools of the KA Toolkit are general and the only customization necessary will be the setting of certain parameters.
Figure 2 represents the team of experts, each using a personal KA Agent, and collaborating to jointly build the KB. The team leader supervises the entire process, while individual domain experts are responsible for building parts of the KB that share common knowledge.
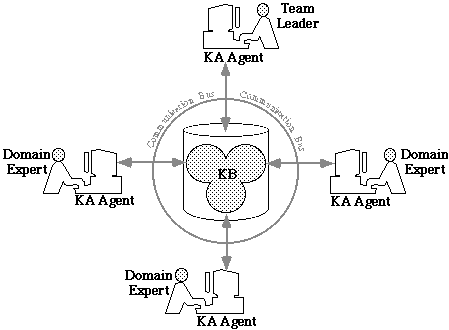
Figure 2: A team of domain experts collaborating for developing a KB.
After the KA Agents are built, their translation, editing and browsing capabilities are used to initialize the KB from a library of reusable ontologies, common domain theories, and generic problem solving strategies (Neches et al. 1991; Genesereth and Ketchpel, 1994). Alternatively, the KB could be initialized from an existing knowledge base, such as the CYC knowledge base (Guha and Lenat, 1994), or from a knowledge base generated with foundation building tools developed as part of the HPKB research effort.
Several features of the proposed approach facilitate collaborative knowledge acquisition:
- The knowledge is represented in the form of a semantic network that defines the terms of the representation language, and rules that are expressed using these terms. As a consequence, the domain experts have to agree on some of the terms of the representation language but they could develop the rules independently.
- The KB to be built is divided into parts that are as independent as possible, and each domain expert is assigned the development of one of the parts. The team leader manages the partitioning and the integration of the KB, and facilitates a consensus between the experts.
- The KA Agents assist the team leader and the individual domain experts in building the KB (see Figure 2). Each domain expert will teach his/her KA Agent rules corresponding to one part of the KB to be built. Occasionally, this process will require the definition or modification of terms in the representation language. When such events occur, the KA Agents facilitate a consensus between the experts concerning the involved terms. They send and receive messages with information that needs to be known or agreed upon by several experts. They also keep track of the KB parts built by each expert, and of their shared knowledge, to determine which domain experts need to be informed or asked to agree upon some modifications made by another expert.
The most innovative aspect of our proposal is the process of teaching the KA Agents. This process is based on a cooperation between each KA Agent and a human expert in which the agent helps the expert to express his/her knowledge using the agent's representation language, and the expert guides the learning actions of the agent. The central idea is the use of the synergism:
- First, it is the synergism between teaching (of the agent by the expert) and learning (from the expert by the agent). For instance, the expert will select representative examples to teach the agent, will provide explanations, and will answer agent's questions. The agent, on the other hand, will learn general rules that are difficult to be defined by the expert, and will consistently integrate them into the KB.
- Second, it is the synergism between different learning methods employed by the knowledge acquisition agent. By integrating complementary learning methods (such as inductive learning from examples, explanation-based learning, learning by analogy, learning by experimentation) in a dynamic, task-dependent way, the agent is able to learn from the human expert in situations in which no single strategy learning method would be sufficient (Tecuci, 1993; Michalski and Tecuci, 1994).
Figure 3 shows the most important processes of the proposed tutoring-based knowledge acquisition. They are Knowledge Elicitation, Rule Learning, KB Refinement, and Exception Handling.
During Knowledge Elicitation the expert uses the editing and browsing tools to define knowledge that he/she could easily express.
During Rule Learning, the expert is teaching the agent how to solve domain specific problems. He/she will show the agent how to solve a typical problem and will help it to understand the solution. The agent will use learning from examples, from explanations and by analogy to learn a general plausible version space rule that will allow it to solve similar problems.
During KB Refinement the agent employs learning by experimentation, inductive learning from examples and learning from explanations, to refine the rules in the KB. These could be either rules learned during the Rule Learning process, rules directly defined by the expert during Knowledge Elicitation, or rules that have other origins (for instance, rules transferred from another KB). Rule refinement will also determine a refinement of the concepts from the semantic network.
During KB refinement the agent may encounter exceptions to a rule. A negative exception is a negative example that is covered by the rule where specializing the rule to uncover it results in uncovering some positive examples. Similarly, a positive exception is a positive example that is not covered by the rule and generalizing the rule to cover it results in covering some negative examples. One common cause of the exceptions is the incompleteness of the knowledge base that does not contain the terms to distinguish between the rule's examples and exceptions. During Exception Handling, the agent will guide the expert to provide additional knowledge that will extend the representation space for learning such that, in the new space, the rules could be modified to remove the exceptions.
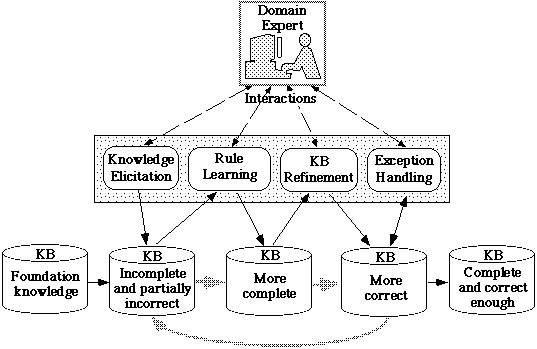
Figure 3: The main processes of knowledge acquisition.
The Exception Handling process may lead to the extension of the description of certain concepts from the KB, or may even lead to the definition of new terms. When such events occur, the KA Agents facilitate a consensus between the experts concerning the involved terms. They send and receive messages with information that needs to be known or agreed upon by several experts. They also keep track of the KB parts built by each expert, and of their shared knowledge, to determine which domain experts need to be informed or asked to agree upon some modifications made by another expert. The KA Agent makes use of the functions of the Association Browser. This tool maintains all the associations between the knowledge base elements. For instance, it can find all the rules that use a certain term.
It should be noticed that exceptions to general rules and concepts will also be accumulated during the normal use of the KB by various applications. Also, various changes in the application domains (for instance, in the case of military simulations, change in weapon systems, or in the modeling of the environment) will require corresponding updates of the KB. In such cases the same processes of Knowledge Elicitation, Rule Learning, KB Refinement and Exception Handling will be invoked in a Retraining Process. That is, in the proposed approach, knowledge maintenance over the life-cycle of the knowledge base is no different from knowledge acquisition. Indeed, because the whole process of developing the knowledge base is one of creating and adapting knowledge pieces, this creation and adaptation may also occur in response to changes in the environment or goals of the system.
Through such processes, the KB will be expanded, completed and tested by a team of domain experts. The resulting KB could be used in different ways:
- Efficient problem solvers could operate directly on this knowledge base;
- The KB could be translated into the representation language of an efficient problem solver;
- A part of this knowledge base could be compiled/optimized into a specialized KB tailored to the unique requirements of an application.
We will keep all such options open and will be prepared to support the integration of the KA toolkit into an Integrated Knowledge Base Development Environment that may require a specific approach.
Intuitive Illustration of the Proposed Approach
In the following sections we will briefly illustrate some aspects of the proposed apprenticeship multistrategy learning approach in two different domains, in order to show its general applicability. The first illustration concerns acquiring knowledge that represents the expertise of a company commander. Such knowledge may be part of the comprehensive battlefield KB corresponding to the first class of challenge problems mentioned in the PIP for BAA 96-43. The second illustration concerns acquiring geographic knowledge. This may be part of the KB with general knowledge for information retrieval corresponding to the second class of challenge problems mentioned in the PIP for BAA 96-43.
Acquiring Knowledge Representing the Expertise of a Company Commander
In this illustration, the KA Agent acts as the apprentice of a human company commander. First, an initial KB has to be built. This initial KB consists of a semantic network that represents information from a terrain database at a conceptual level, as well as generic and specific knowledge relevant to the tasks the agent is trained to perform. A portion of a semantic network is represented in Figure 4. Some nodes in the semantic network represent map regions as objects such as hill-sector-875-1 and hill-868 (see also Figure 5), while others represent general concepts like hill-sectors or hills. These concepts are organized in a generalization hierarchy (the gray links in Figure 4) which relates a concept to a more general concept. This hierarchy is very important not only for the inheritance of properties but also for learning. The objects are further described in terms of their features (such as PART-OF, IN, VISIBLE). The agent also maintains a correspondence between each concept in the semantic network (e.g., hill-sector-875-1) and the corresponding region on the map that it represents (see Figure 5).
Once the initial knowledge base is defined, the military expert trains the agent how to accomplish various missions the way the expert might train a human, by giving examples of tasks and solutions, explaining correct and incorrect solutions, and supervising the agent as it performs new tasks.
To illustrate Rule Learning, let us consider that the military expert is using the ModSAF interface (Ceranowicz, 1994) to train the agent how to place a company to defend an area. The military expert initiates the training session by showing the agent a specific example of a correct placement. The military expert places the three platoons of Company D on the ModSAF map, to defend the company's area of responsibility, as indicated by the placement shown on the left hand side of Figure 5. The agent interacts with the military expert to "understand" why the indicated solution is correct. It uses plausible reasoning to propose explanations why the solution is correct and may receive additional explanations from the military expert. For instance, one explanation why this placement is correct is that these platoons are placed in Company D's area of responsibility, in positions where they can see the engagement area.
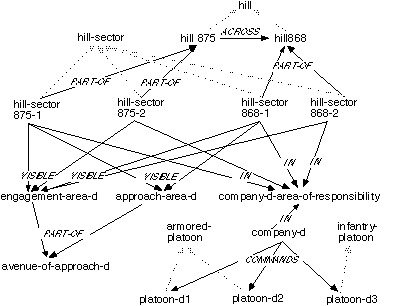
Figure 4: Semantic Network
Using only the problem, its solution, and the explanations, the agent is able to learn a complex plausible version space rule such as the one in Figure 6.
Key to rule learning is the process of understanding why the example is correct, and that of generalizing the explanation to an analogy criterion. Based upon the results obtained so far (Tecuci and Hieb, 1996), we propose to investigate the following areas of rule learning:
- Various types of interactions by which the expert may give hints to the agent (such as pointing to an important object from the example) and may guide the agent in understanding the example.
- Advanced techniques for explanation generation, involving both plausible and deductive reasoning.
- Advanced techniques for multitype (deductive, inductive, and analogy-based) generalization of the example and the explanation into an analogy criterion, to make better use of agent's knowledge for rule learning.
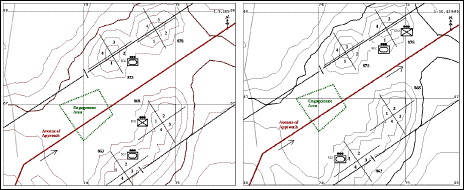
Figure 5: Placing units while learning and refining rules for company placement.
During KB Refinement, the learned rule is used by the KA Agent to generate other placements for defensive missions by analogy with the example provided by the military expert. These placements are shown to the military expert, who will accept or reject them, implicitly characterizing them as positive or negative examples of the general placement rule being refined. For instance, the agent generates the placement shown in the right hand side of Figure 5. The expert rejects this placement and explains that the position of the infantry unit is too far away from the area of engagement. Such an explanation is used by the KA Agent to modify the rule so that it will always lead to placements where the infantry platoon is placed close to the area of engagement. Through such easy and natural interactions, the agent refines the plausible version space rule. An example of such a partially refined rule is shown in Figure 6. The conclusion of the rule is a problem and solution (e.g., in ModSAF, a mission and the way to accomplish it). The IF part of the rule consists of two conditions formed with the concepts and relationships from the semantic network (see Figure 4). These conditions represent a plausible version space for a hypothetical exact condition. The plausible lower bound is an expression that, as an approximation, is less general than the hypothetical exact condition of the rule. By this we mean that most of the instances of the plausible lower bound are also instances of the hypothetical exact condition. The plausible upper bound is an expression that, as an approximation, is more general than the hypothetical exact condition. Figure 6 shows graphically the relationships between these three concepts: the hypothetical exact condition of the rule, the plausible lower bound, and the plausible upper bound. During rule refinement, the plausible lower bound and the plausible upper bound are both generalized (i.e., extended) and specialized (i.e., contracted) to better approximate the hypothetical exact condition.
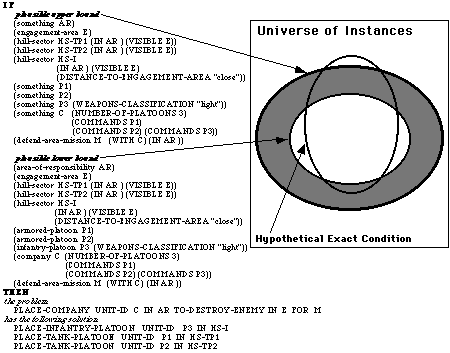
Figure 6: A rule for defensive placement.
The following are some key aspects of rule refinement that we propose to address:
- The selection of the analogous examples generated by the agent. On the one hand we would like to learn rules very fast, from as few examples as possible. On the other hand, however, we would like to learn rules that are verified by more examples which are uniformly distributed in the space covered by the rule. That is, the examples have to be selected in such a way that, at the end of the rule refinement process, they represent a good enough testing set to consider that the rule is correct.
- Powerful generalization and specialization methods for the rule's bounds should be developed. In particular, methods for generalization and specialization of numeric elements should be developed.
- Methods to facilitate the explanation of negative examples and automated generation of appropriate negations of these explanations should be found, because these negations are a powerful means by which to refine the rule.
- Methods to guide the refinement of rules by using other sources of information besides the expert, such as a repository of existing examples, should also be developed.
The limited experiments that we have conducted so far show that this approach is very efficient, leading to learning complex rules from only 5 to 10 examples analyzed by the expert (Tecuci and Hieb, 1996).
Acquiring Geographic Knowledge
The proposed knowledge acquisition approach is general and we have preliminary evidence of its applicability in a variety of domains. Let us suppose, for instance, that we want to build a knowledge base in the domain of geography. The experts can teach the KA Agents general inference rules by providing specific examples of facts and helping the agents to understand why they are true. For instance, an expert could indicate the agent that rice grows in Cambodia. The agent uses plausible reasoning to propose explanations of why this fact is true and may receive additional explanations from the expert. One explanation of why rice grows in Cambodia is that the water supply of Cambodia is high and rice needs a high water supply. From such explanations, the agent will form a general rule for inferring if a plant grows in a certain area. To refine this rule, it will ask the expert specific questions like, "is it true that corn grows in Illinois?", and will thus obtain additional positive or negative examples of the rule, as well as explanations of why a certain plant does not grow in a certain area. Based on only a few such examples and explanations it will learn and refine a general rule like the one in Figure 7.
IF (plant x (NEEDS-WATER-SUPPLY t) (NEEDS-CLIMATE u) (NEEDS-TERRAIN z) (NEEDS-SOIL v)) (place y (WATER-SUPPLY t) (CLIMATE u) (TERRAIN z) (SOIL v)) (terrain-type z) (quantity t) (climate-type u) (soil-type v) THEN (plant x (GROWS-IN y))
Figure 7: A rule for inferring if a plant grows in a certain area.
Final Remarks
The basis for the Collaborative KA Toolkit is the Disciple Toolkit that we have built with partial support from the DARPA CAETI Program. Without being a collaborative toolkit, the Disciple Toolkit already contains initial versions of some of the tools that we propose to develop, and therefore illustrates some of the features of the KA Toolkit. While much work remains to be done, we believe that our approach holds much promise to achieve many of the knowledge acquisition related goals of the HPKB research initiative.
Bibliography
Buchanan B.G. and Wilkins D.C., Eds. (1993). Readings in Knowledge Acquisition and Learning: Automating the Construction and Improvement of Expert Systems, Morgan Kaufmann, San Mateo, CA.
Ceranowicz, A. Z. (1994). "ModSAF Capabilities," in the Proceedings of the Fourth Conference on Computer Generated Forces and Behavioral Representation, Orlando, Florida.
Genesereth M.R. and Ketchpel S.P. (1994), Software Agents, Communications of the ACM, Vol. 37, No. 7.
Guha R.V. and Lenat D.G. (1994). Enabling Agents to Work Together, Communications of the ACM, Vol. 37, No. 7.
Michalski R.S. and Tecuci G. (1994). Machine Learning: An Multistrategy Approach, Vol. 4, San Mateo, CA, Morgan Kaufmann.
Mitchell T.M. (1997). Machine Learning, McGraw Hill, to appear.
Neches R., Fikes R., Finin T., Gruber T., Patil R., Senator T., and Swartout W. (1991). Enabling Technology for knowledge sharing. AI Magazine, Vol.12, No. 3.
Shavlik J. and Dietterich T. , Eds. (1990). Readings in Machine Learning, Morgan Kaufmann, San Mateo, CA.
Tecuci G. (1992a). "Cooperation in Knowledge Base Refinement," in D. Sleeman and P. Edwards (eds.), Machine Learning: Proceedings of the Ninth International Conference (ML92), pp. 445-450, Morgan Kaufmann, San Mateo, CA.
Tecuci G. (1992b). Automating Knowledge Acquisition as Extending, Updating, and Improving a Knowledge Base, IEEE Trans. on Systems, Man and Cybernetics, 22, pp. 1444-1460.
Tecuci G. (1993). "Plausible Justification Trees: a Framework for the Deep and Dynamic Integration of Learning Strategies," Machine Learning Journal , vol.11, pp. 237-261.
Tecuci G. (1995) "Machine Learning and Knowledge Acquisition: Integrated Approaches," Tutorial Notes, The International Joint Conference on Artificial Intelligence, 143 pages, IJCAI-95, Montreal, Canada.
Tecuci G. and Hieb M. H. (1994). Consistency-driven Knowledge Elicitation: Using a Learning-oriented Knowledge Representation that Supports Knowledge Elicitation in NeoDISCIPLE, Knowledge Acquisition Journal, 6, pp. 23-46.
Tecuci G. and Hieb M.H. (1996). "Teaching Intelligent Agents: The Disciple Approach," International Journal of Human-Computer Interaction, vol.8, no.3, pp.259-285.
Tecuci G. and Kodratoff Y. Eds. (1995). Machine Learning and Knowledge Acquisition: Integrated Approaches, Academic Press.